# Spring Cloud Stream
如何设计并实现,能通过异步消息与其它微服务互相交互的微服务。
使用异步消息在应用间互相通信并不是什么新概念,新的概念是使用消息来传达事件状态的改变——Event Driven Architecture(EDA),即事件驱动架构,也可以称为 Message Driven Architecture(MDA),消息驱动架构。
基于事件驱动架构,我们可以构建高度解耦的系统,需要互相通信的服务不用通过特定的库或其它服务紧密耦合在一起。当与微服务结合时,我们只需让服务监听应用程序发出的事件(消息)流,接收到事件(消息)后作出对应的响应,就可以在应用程序中快速添加新功能。
Spring Cloud 的子项目Spring Cloud Stream,能让基于消息驱动的应用开发变得更加简单,使用它,我们可以很容易地就能实现“消息发布和消费”,而且会对底层消息传递平台(后文会介绍)屏蔽服务(包括发布者和消费者)的实现细节。
# 消息传递、事件驱动架构和微服务
在基于微服务的应用中,为什么消息传递的地位如此重要?
回答这个问题时,我们会用到整个教程都涉及到的两个服务—— license 和 organization 服务。
不妨想象一下,当这些服务部署到生产环境中后,发现 license 服务在访问 organization 服务获取 organization 信息的时候,需要花费很长时间。不过幸运的是,发现了 organization 数据的使用模式是:organization 的数据很少变更,而且是使用主键从 organization 服务获取数据的。
所以将 organization 服务获取的数据缓存起来,这样一来就能大大降低访问 license 服务时的响应时间(获取 license 数据时需要获取对应的 organizationId 的 organization 数据)。
在使用实现缓存的解决方案时,需要特别注意的有三点:
需要保证 license 服务所有实例获取到的缓存数据保持一致。这意味着不能将数据缓存到 license 服务每个实例中,因为我们需要保证不管哪个实例来获取数据,都要保证返回的 organization 数据是一致的。
不能将 organization 数据缓存在托管 license 服务的容器的内存中。服务托管在的容器的资源一般都是有限的,而且本地缓存会引入更大的复杂性,因为必须确保本地缓存与集群中的其它服务实例的缓存是同步的。
当一个 organization 记录发生改变,比如更新或删除,license 服务就需要去确认 organization 服务的哪些数据状态发生了变更。然后 license 服务需要让发生变更的 organization 缓存数据无效并从缓存中移除或更新。
针对上面说的三点,现在有 2 个解决方案。
第一种,使用同步的“请求-响应”模式
当 organization 数据状态发生变更,license 和 organization 服务通过它们各自的 REST 端点来回通信,比如 organization 调用 license 服务的端点通知 license 某个 organization 的状态发生改变,你那边的缓存需要做处理,license 处理完后响应 organization 服务。
第二种,organization 服务在数据发生变更后,organization 服务将这一变更通过异步事件(消息)发送出去;换句话说,organization 服务会将某个 organization 记录发生了变更这一事件发布到一个队列中,而 license 服务一直在监听消息传递平台,当监听到队列中有新的事件(来自 organization 数据变更的事件)后,会“消费”这一事件,即对缓存做对应的处理——更新或移除。下面进一步介绍这两种方案的实现细节。
# 同步的“请求-响应”模式
为缓存 organization 数据,我们使用 Redis 数据库来存储。redis 是一个分布式的以键值对的形式来存储数据的数据库。下图说明了如何使用“请求-响应”模式来实现缓存的。
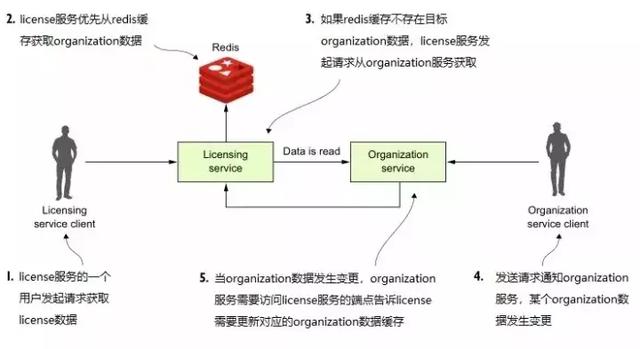
上图中,当用户请求 license 服务,license 服务也需要查询获取 organization 数据。license 服务会优先根据 organization Id 从集群 redis 中获取数据,如果找不到,license 服务则会向 organization 服务发送请求,得到正确返回结果之后,返回 license 数据给用户之前,license 服务会把 organization 数据存储到 redis 中。此时,若有人通过 organization 的端点更新或删除 organization 记录,那么 organization 服务在完成业务逻辑后,还需要访问 license 服务,告知对应的 organization 记录已经无效,需要更新或从缓存中删除。这一步中,至少存在三个问题/隐患:
organization 和 license 服务高度耦合。
这种耦合会使服务间交互的灵活性变脆弱。如果 license 服务提供的更新缓存的端点变更,那么 organization 服务也需要跟着改变。
这种方案极不灵活。因为我们无法在不修改 organization 服务源码的情况下,给“organization 数据的变更”这一事件添加新的消费者,即当 organization 数据变更后,别的服务也做相应的业务逻辑。
下面对这 3 点做进一步分析。
服务间高度耦合
在之前的图中,我们可以看到 license 和 organization 服务间紧密耦合。license 服务依赖 organization 服务获取数据,另外,当 organization 记录发生变更后,organization 服务还需要访问 license 服务,通知缓存中的哪个 organization 已经失效,所以 organization 服务需要 license 服务暴露一个端点来完成这一需求,这样一来,organization 服务也跟 license 服务耦合在一起。当然,还有另一种做法,organization 服务直接与 license 服务的 redis 服务器交互,让 redis 中的某条记录失效。
但是,organization 服务直接与 license 服务的 redis 服务器交互这一做法在微服务环境中本身就是一大禁忌。当然,肯定会有人反驳说:缓存中的数据本身就是属于 organization 服务的,license 服务只是在特定上下文使用它们或者围绕这些数据构建业务。但是,让 organization 服务直接 license 服务 redis 中的数据打交道,会使 organization 服务依赖于 license 服务的 redis,也极易打破 license 服务已经建立实现的规则。
服务变得脆弱
license 和 organization 服务的高度耦合会使这两个服务变得更脆弱。如果 license 服务挂掉或处理能力下降,organization 服务也会因此受到影响,因为 organization 服务现在需要直接与 license 服务交互,即依赖于 license 服务。
为 organization 服务添加消费者不灵活
如果有另一个服务也需要“监听”organization 数据的改变,那么必须在 organization 服务为这一服务添加一个远程调用逻辑。这意味着 organization 必须添加新的代码并重新编译、部署。想一想,如果以后有多个这样的服务(需要消费 organization 数据变更事件),甚至许多类似 organization 服务和 license 服务这样高度耦合在一起的服务群,并且使用同步的“请求-响应”模式,那么应用内服务的“织网”表演将从此开始。最后你会发现,这个应用的失败,这张“网”占了很重的分量。
# 使用消息传递实现服务间的交互
使用消息传递方案,将会在 license 服务和 organization 服务间引入一个消息队列。该队列并不是用来从 organization 服务获取数据,而是当 organization 服务数据发生变更后,可以将这一消息发布到队列中。下图说明了具体细节:

上图展示的模式,每一次 organization 数据发生变更,organization 服务会发布消息到队列中。而 license 一直在监听来自 organization 的数据变更消息,当发现队列中发布新的消息后会立刻消费,即根据消息内容执行相应的逻辑,如更新缓存或直接失效。在这一模式中,消息队列扮演的是一个处于 license 服务和 organization 服务的中间人的角色,即前文提到的“底层消息传递平台”。这一模式能带来许多好处,可以简单概括为以下 4 点:
低耦合
持久性
高可扩展性
高灵活性
低耦合
一个微服务应用可以由许多个小的、分散的服务组成,这些服务间大都需要与其他服务交互,而且可能对其它服务管理的数据“感兴趣”。之前提到使用同步的方式,同步的 HTTP 响应会让 license 和 organization 两个服务对彼此产生极大的依赖。虽然,我们无法完全消除这种依赖,但可以尽量让这种依赖减弱,服务只暴露直接管理自己数据的端点。消息传递模型可以解耦两个服务间的依赖,因为对 organization 服务来说,当需要发布数据状态变更的消息,只需将该消息发布到消息队列中;而对 license 服务而言,只负责对消息进行消费,并不关心是谁发布的消息。
持久性
消息队列的存在,可以确保消息一定会被传递出去,即使消费方服务已经挂掉。也就是说,即使 license 服务已经不可用,organization 服务依然可以将消息发布到消息队列中。这些消息会被存储在消息队列中,直到 license 服务可用后才开始消费这些积攒了许多的消息。相反的,缓存和消息队列的结合,当 organization 服务挂掉,license 服务可以优雅的降级,因为至少有部分 organization 数据在 license 服务的缓存中。有时,过时的数据总比缺少数据来得强。
高可扩展性
由于消息发布出去后会存储在消息队列中,所以小心的发布者并不需要等待消费者消费后返回的响应消息,因此它们可以继续它们的工作。同样的,当消费方的一个消费者(实例)已经无法尽快地从队列中读取消息,那么可以启动更多的消费方服务来处理这些“溢出”的消息。而传统的扩展机制是增加处理消息的线程数量,这样,一个消费者就能足以应对。不幸的是,若采用这种办法,那么消息的消费者的处理性能最后将受限 CPU 的核心数量,当服务发布消息频率再次增高,处理熟读又无法满足需求,最后只能通过部署到性能更强大的机器上。而通过启动更多消费者实例这种可扩展性极强的方法则非常适用于微服务模式,因为启动一个微服务的更多实例来相对于性能强大的机器来说是微不足道的,毕竟这些微服务随便部署在普通机器上就能很好地运行。
高灵活性
消息的发布者并不知道谁会去消费这些消息,这意味着可以很轻松地加入新的消息消费者,重要的是这并不会对消息的发布者有任何影响。这是一个非常强大的优势,因为完全可以在添加拥有新功能的微服务到应用中的情况下,不会影响到其它已存在的微服务。新添加的服务只需监听事件的发布然后对其做出响应即可。
# Spring Cloud Stream 简介
Spring Cloud Stream 可以很容易实现将消息传递模式应用到基于 Spring 的微服务应用中。Spring Cloud Stream 子项目官网https://cloud.spring.io/spring-cloud-stream/ (opens new window)。
Spring Cloud Stream 是一个注解驱动框架,所以可以使用简单的几个注解就能在应用中构建消息的发布者和消费者。
Spring Cloud Stream 还支持我们将消息传递平台的实现细节抽象出来,Spring Cloud 只提供与平台无关的接口。这意味着可以将消息传递平台详细的实现细节从应用代码中抽离出来,然后使用已经实现消息传递的平台,Spring Cloud Stream 支持的消息传递平台包括 Apache Kafka 和 RabbitMQ,这样,应用中就可以直接使用与具体平台无关 Spring 接口实现消息的发布和消费。
为了了解 Spring Cloud Stream,我们首先对 Spring Cloud Stream 的架构进行介绍并熟悉 Spring Cloud Steam 相关术语的含义。如果是第一次接触消息传递平台,先打个预防针,接下来涉及的东西学习起来可能会有点吃力。
# Spring Cloud Stream 架构
首先,我们假设两个服务通过消息传递进行交互来介绍 Spring Cloud Steam 的架构。一个是消息发布者,另一个是消息消费者。如下图,借助 Spring Cloud Stream 来实现消息的传递:
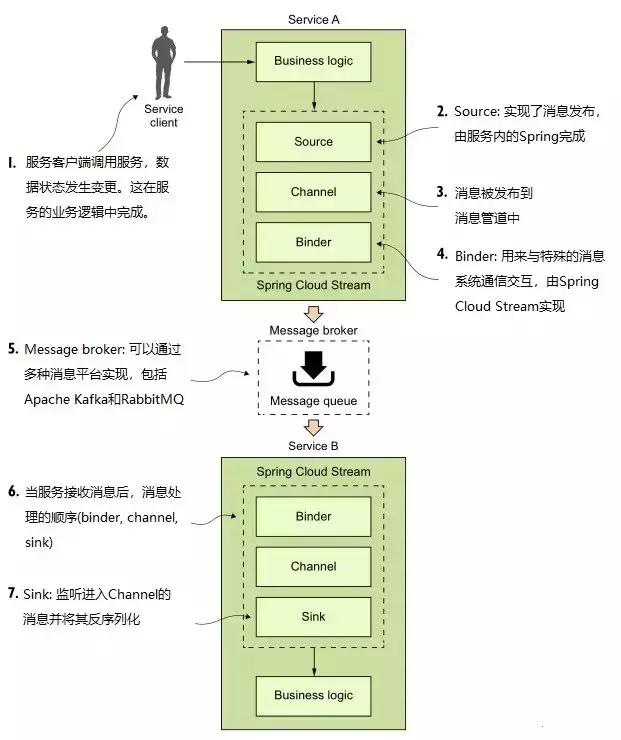
Spring Cloud 中消息的发布和消费涉及到 4 个组件:
Source
Channel
Binder
Sink
# Source
当服务发布消息前的前置业务完成后会通过 Source 将消息发布出去。Source 是一个 Spring 注解接口,它可以将代表消息主体的 POJO 对象发布到消息管道(Channel)中,发布之前会把该消息对象序列化(默认使用 JSON)。
# Channel
Channel(消息管道)是消息队列的进一步抽象,它会保存消息生产者发布的或者消息消费者接收到的消息。消息管道的名称一般与目标队列名称相关联。然而,消息队列的名称不会直接在代码中暴露,相反管道名称则会被用在代码中,所以只能在配置文件中配置,为消息管道选取正确的消息队列进行读和写,而不是在代码中体现。
# Binder
Binder 则是 Spring Cloud Stream 框架的一部分。它是由 Spring Cloud Stream 实现的用来与特殊的消息平台交互。因为 Binder 是由 Spring Cloud Stream 实现的,所以我们可以在不需要暴露特殊消息平台的类库和 API 的情况下就能实现对消息的发布和消费。下文你将会看到它的强大之处。
# Sink
在 Spring Cloud Stream 中,当从消息队列接收到一条消息后,需要通过 Sink。Sink 能监听进入管道中的消息并将消息反序列化成一个 POJO 对象。之后,消息就能给业务逻辑使用了。
# 消息发布和消费的实现
上面我们已经简单介绍了 Spring Cloud Stream 涉及到的几个组件,下面开始编写一个简单的 Spring Cloud 例子。在该例子中,我们会使用 organization 服务发布消息然后 license 服务消费消息,license 服务接收到消息后只做最简单的消费——在控制台打印日志。
# 在 organization 服务实现消息发布者
接下来我们会实现,每当服务维护的 organization 数据发生变更(添加、更新或删除)时,organization 服务会向一个 RabbitMQ topic 发布一条消息,表明 organization 数据变更事件已经发生。
发布出去的消息包含与该数据变更事件相关的 organization ID 和数据变更行为(添加、更新或删除)。
pom 文件
实现消息的发布,第一件事就是在 pom 文件引入需要的启动依赖。启动依赖很简单,只有一个,在 organization 服务的 pom 文件中添加如下依赖:
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
核心类
引入需要的依赖后,我们就可以大展拳脚了。Show Time!
首先,来看下在消息发布端需要创建的几个类或接口,如下图:
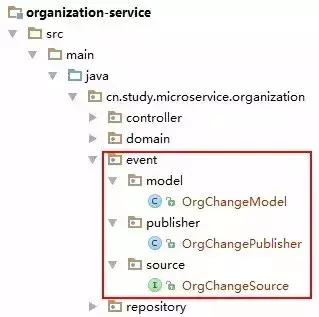
其中包含两个类一个接口,看它们的名字大概就能猜出各自的作用了。下面来看具体源码:
OrgChangeModel 类:
public class OrgChangeModel {
private String type;
private String action;
private String organizationId;
private String correlationId;
}
若仔细观察 OrgChangePublisher 的代码,大概可以猜出,该类其实就是一个消息模型,是一个 POJO,是用来承载需要传递的消息,换句话说就是消息的载体。另外该模型在被发送出去的时候,会被序列化成 json(默认)。
OrgChangeSource 接口:
public interface OrgChangeSource {
@Output("orgChangeOutput")
MessageChannel output();
}
OrgChangeSource 接口很简单,现在只有一个方法,该方法返回的是一个 MessageChannel,但不简单的是该方法上面的注解——@output,加上@output 注解,Spring Cloud Stream 会自动实现一个返回 MessageChannel(消息管道)的方法。另外,注解@output 有一个属性——value,用来自定义方法返回的消息管道的名称。
OrgChangePublisher 类:
@EnableBinding(OrgChangeSource.class)
@Component
public class OrgChangePublisher {
private static final Logger logger = LoggerFactory.getLogger(OrgChangePublisher.class);
@Autowired
private OrgChangeSource source;
public void publish(String action, String orgId) {
OrgChangeModel model = new OrgChangeModel();
model.setAction(action);
model.setOrganizationId(orgId);
model.setType(OrgChangeModel.class.getTypeName());
logger.info("sending rabbitmq message {} for Organization Id: {}", action, orgId);
source.output().send(MessageBuilder.withPayload(model).build());
}
}
首先可以看到该类上面有一个@EnableBinding 注解,下图是官方文档对该注解的介绍:

从上图可以知道,@EnableBinding 可以让一个 Spring 应用变成一个 Spring Cloud Stream 应用,该注解可以加在应用中的其中一个配置类上。另外,该注解中也只有一个 value 属性,用来接收一个 Class 类(在我们看来其实是接口)数组,这些 Class 类包含一个或多个接口方法,如上面的 OrgChangeSource,这些方法都返回可绑定的组件(Channel)。
接着再来看 OrgChangePublisher#publish()方法的逻辑。其中最关键的一步就是:
source.output().send(MessageBuilder.withPayload(model).build());
我们知道 source 是 Spring 注入的由 Spring Cloud Stream 帮我们实现的 Source 实例,(注意,只有@EnableBinding 的 value 包含了对应的 Source 接口,此处为 OrgChangeSource,Spring Cloud Stream 才会知道需要帮我们实现,若去掉@EnableBinding 注解中的 OrgChangeSource.class,将无法成功启动服务),output()方法是我们之前在 OrgChangeSource 中定义的接口方法,返回的是一个实现 MessageChannel 接口的对象,其中只有两个 send 方法。方法签名分别为:
boolean send(Message message);
boolean send(Message message,long timeout);
Channel#send()方法能将一个 Message 发送到这个 Channel 中。如果发送成功返回 true。这个方法可能会无限期阻塞,取决于使用哪种实现。所以第二个方法的 timeout 参数就是来控制超时时间的。send 方法在发送消息时会阻塞线程,直到消息发送成功或超时发送失败。
而 MessageBuilder 是默认的消息构建器,它的静态方法 withPayload()接收的就是我们需要发送的消息(负载),返回的是一个 MessageBuilder 对象,MessageBuilder 对象调用 build()方法最终产生一个 Message 对象。最后由 send()方法发送到 Channel 中。
发布消息
我们的目的是在 organization 数据发生变更后,通过消息传递将这一信息通知 license 服务。接下来介绍如何使用 Publisher 来发布消息。
修改 OrganizationService 类的 updateOrg()和 deleteOrg()方法,如下:
@Service
@Slf4j
public class OrganizationService {
@Autowired
private OrganizationRepository orgRepository;
@Autowired
private OrgChangePublisher orgChangePublisher;
public Organization getOrg(Long organizationId) {
return orgRepository.findById(organizationId).get();
}
public void updateOrg(Organization org) {
Organization save = orgRepository.save(org);
log.info("success save {} to database", save);
orgChangePublisher.publish("update", String.valueOf(org.getId()));
}
public void deleteOrg(Organization org) {
orgRepository.deleteById(org.getId());
orgChangePublisher.publish("delete", String.valueOf(org.getId()));
}
}
可以看到,在 OrganizationService 中注入了 OrgChangePublisher,然后在 update()和 delete()方法中使用,即 organization 记录更新或删除成功后会将消息发布出去。
配置文件
当所有核心类实现后,最后一步是配置使用哪种消息中间件及其环境,还有消息管道的绑定关系。配置如下:
spring:
cloud:
stream:
binders:
rabbitmq:
type: rabbit
environment:
spring:
rabbitmq:
host: 192.168.1.8
port: 5672
username: admin
password: admin
bindings:
orgChangeInput:
destination: orgChangeTopic
content-type: application/json
group: licenseGroup
binder: rabbitmq
可以看到,主要涉及到两个属性的配置:spring.cloud.stream.binders 和 spring.cloud.stream.bindings,这两个属性都接收一个 Map 集合,即可以配置多个 binder 和 管道(Channel)。binders Map 的键值是 binder 的名称,这个名称需要在 bindings 配置中用到;binding 的键值是定义的管道的名称,取注解@Output 和@Input 的 value 值,如 OrgChangeSource#output()方法上注解@Output 的 value 值"orgChangeOutput"。其它属性的含义如下图所示:

这样,消息发布者的工作就全部完成,接下来是实现消息消费者。
# 在 license 服务实现消息消费者
pom 文件
同样,license 服务也需要引入消息驱动的启动依赖。跟消息发布者引入的依赖一样:
org.springframework.cloud:spring-cloud-starter-stream-rabbit
核心类
下图是消息消费端需要创建的几个类或接口:
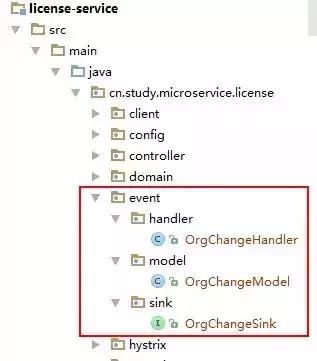
OrgChangeModel 类:
OrgChangeModel.java 必须与 organization 服务的一样,因为 license 服务会在接收到消息后将消息内容(Model)反序列化,所以消息发布端和消费端的消息模型(Model)必须保持一致。一般会将消息模型提取到一个公共库,然后发布端和消费端就可以引用同一个了。这里就不给出源码了。
OrgChangeSink 接口
public interface OrgChangeSink {
@Input("orgChangeInput")
SubscribableChannel input();
}
上面的接口同样只有一个方法,与 OrgChangeSource 不同的是,该接口方法上的注解变成@Input,但原理与@Output 差不多,注解中的"orgChangeInput"同样的 Channel(管道)的名称。该接口同样是交由 Spring Cloud Stream 来实现。
OrgChangeHandler
@EnableBinding(OrgChangeSink.class)
@Slf4j
public class OrgChangeHandler {
@StreamListener("orgChangeInput")
public void handle(OrgChangeModel model) {
log.info("Received a message of type {} , model = {}", model.getType(), model);
switch (model.getAction()) {
case "get":
log.info("Received a GET event from the organization service for organization id {}", model.getOrganizationId());
break;
case "save":
log.info("Received a SAVE event from the organization service for organization id {}", model.getOrganizationId());
break;
case "update":
log.info("Received a UPDATE event from the organization service for organization id {}", model.getOrganizationId());
break;
case "delete":
log.info("Received a DELETE event from the organization service for organization id {}", model.getOrganizationId());
break;
default:
log.error("Received an UNKNOWN event from the organization service of type {}", model.getType());
break;
}
}
}
将接收到的消息反序列化成对应的 Model 后,就可以使用 Model 做相应的业务了。这里只是在控制台中打印。实际开发中就不会这么简单了,比如需要操作数据库等等。
源码中还出现了一个注解@StreamListener,该注解能用来接听某个管道,当监听到管道中有消息到来,机会接收然后将消息反序列化,最后执行相应的业务,这里为 handle()方法。
消费端的核心代码已经介绍完,最后还需要配置一些必要的属性。
配置文件
配置如下:
spring:
cloud:
stream:
binders:
rabbitmq:
type: rabbit
environment:
spring:
rabbitmq:
host: 192.168.1.8
port: 5672
username: admin
password: admin
bindings:
orgChangeInput:
destination: orgChangeTopic
content-type: application/json
group: licenseGroup
binder: rabbitmq
application:
name: license
server:
port: 8082
消费端的配置与发布端的配置绝大多数是一样的,不一样的是在配置 OrgChangInput Channel 的时候,多了一个属性:OrgChangInput.group。实际上,一个消息发布者可以有多个消息消费者,也就是说,还可以有另外的服务也去监听 organization 服务发布的同一个消息事件。分组的作用是将不同的服务隔离开,服务间的监听互不影响,若不分组,那么发布的消息,只有其中的某个服务的能接收到并消费;而分组后,会将消息的副本分别发送到所有监听该消息事件的服务对应的管道中,最后消息会由服务的某个实例消费。
发布并消费消息
最后启动 organization 服务和 license 服务。然后使用 postman 访问http://localhost:11000/v1/organizations/e254f8c-c442-4ebe-a82a-e2fc1d1ff78a,http 方法为 PUT,请求体为:
{
"id": "e254f8c-c442-4ebe-a82a-e2fc1d1ff78a",
"name": "customer-crm-co",
"contactName": "Mark Balster",
"contactEmail": "mark.balster@custcrmco.com",
"contactPhone": "823-555-1213"
}
然后,观察 organization 服务和 license 服务的控制台,可以看到类似如下输出:
organization 服务控制台输出:

license 服务控制台输出:

证明 license 服务接收到由 organization 服务发布的消息,并消费(打印日志)了。